
Video Anomaly Detection
VAD Framework Diagram
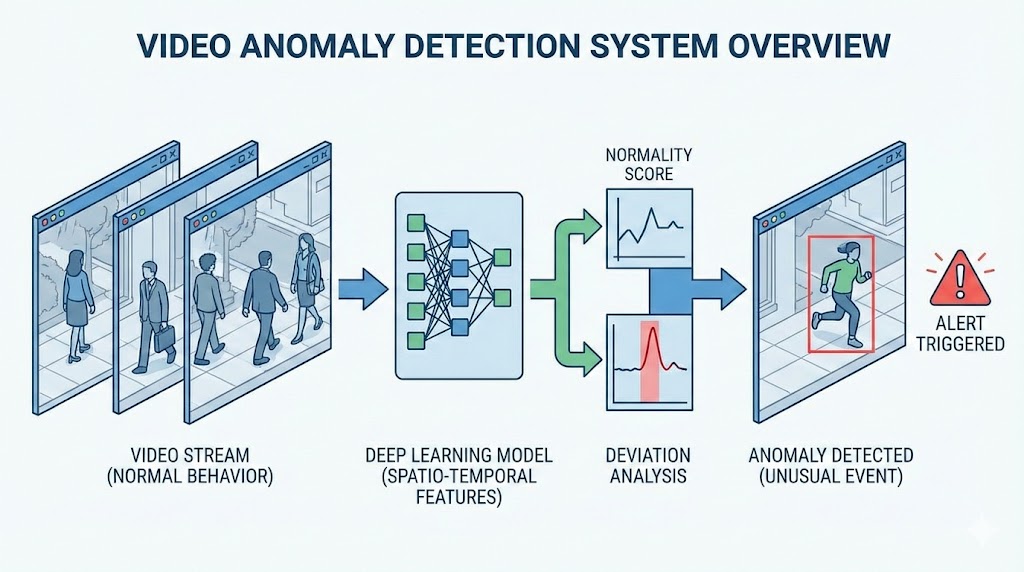
Task Description
Video Anomaly Detection is a significant research area within the fields of computer vision and machine learning, aimed at automatically identifying unusual or irregular behaviors within video data. This technology is crucial for applications such as surveillance, security monitoring, traffic control, and healthcare monitoring, where it enhances efficiency and reduces reliance on human oversight. The primary goal of video anomaly detection is to automatically flag events or activities that deviate from learned normal behavior patterns, which are typically established through training data. This field faces key challenges including the diversity and ambiguity in defining what constitutes an anomaly, the scarcity of labeled anomaly data which limits the use of traditional supervised learning models, and the need for real-time processing capabilities to handle large-scale video data effectively. As such, researchers in this domain often employ unsupervised learning techniques to detect anomalies due to the rarity of anomaly instances, and also explore semi-supervised and few-shot learning paradigms to better leverage limited labeled data.
Selected Papers
Exceptional Contribution
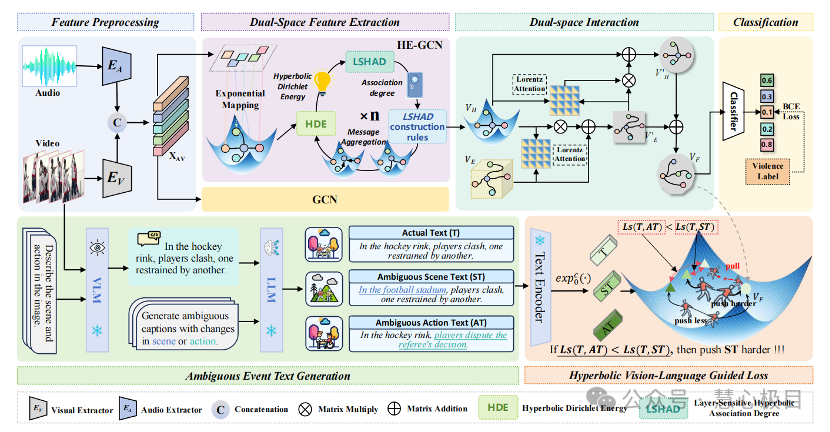
PiercingEye: Dual-Space Video Violence Detection with Hyperbolic
Vision-Language Guidance

Jiaxu Leng, Zhanjie Wu, Mingpi Tan, Mengjingcheng Mo, Jiankang Zheng,
Qingqing Li, Ji Gan, Xinbo Gao*
Focusing on the problem of anomaly understanding in UAV aerial video scenes, we propose the first reasoning-oriented large-scale UAV anomaly understanding benchmark dataset, A2Seek. This dataset contains 23 hours of 4K UAV aerial videos, covering 27 typical campus scenes and over 20 types of anomalies, integrating RGB and infrared modalities, and providing frame-level timestamps, region-level annotations, and causal reasoning explanations, enabling algorithms to be comprehensively evaluated on three levels: "whether there is an anomaly," "where the anomaly is," and "why it occurs." On this basis, the team proposed the reasoning-driven framework A2Seek-R1, which activates model reasoning capabilities through Graph-of-Thought (GoT) supervised fine-tuning, and designed the A-GRPO reinforcement learning algorithm for aerial scenes, allowing the model to dynamically focus on anomalous regions and output interpretable reasoning chains. Experiments show that A2Seek-R1 improves prediction accuracy by 22.04% and anomaly localization mIoU by 13.9% compared with existing methods, demonstrating strong generalization in complex environments and out-of-distribution scenarios.
Conference on Neural Information Processing Systems(NeurIPS),2025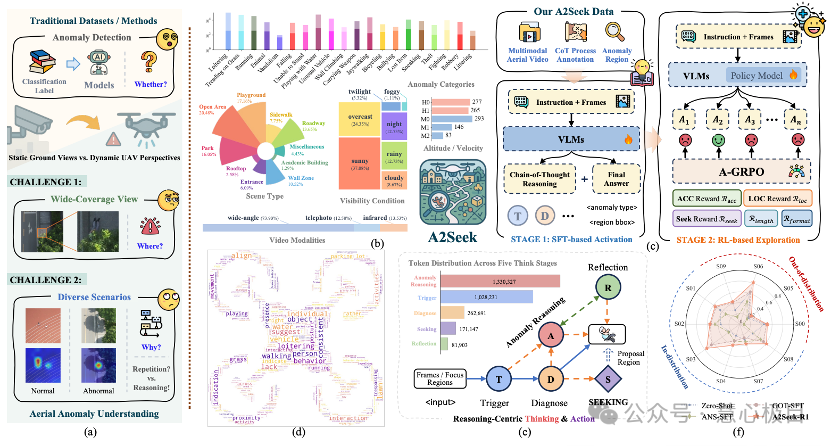
A2Seek: Towards Reasoning-Centric Benchmark for Aerial Anomaly
Understanding
Mengjingcheng Mo1, Xinyang Tong, Mingpi Tan, Jiaxu Leng1,Jiankang Zheng,
Yiran Liu, Haosheng Chen, Ji Gan1, Weisheng Li, Xinbo Gao*
Focusing on the problem of anomaly understanding in UAV aerial video scenes, we propose the first reasoning-oriented large-scale UAV anomaly understanding benchmark dataset, A2Seek. This dataset contains 23 hours of 4K UAV aerial videos, covering 27 typical campus scenes and over 20 types of anomalies, integrating RGB and infrared modalities, and providing frame-level timestamps, region-level annotations, and causal reasoning explanations, enabling algorithms to be comprehensively evaluated on three levels: "whether there is an anomaly," "where the anomaly is," and "why it occurs." On this basis, the team proposed the reasoning-driven framework A2Seek-R1, which activates model reasoning capabilities through Graph-of-Thought (GoT) supervised fine-tuning, and designed the A-GRPO reinforcement learning algorithm for aerial scenes, allowing the model to dynamically focus on anomalous regions and output interpretable reasoning chains. Experiments show that A2Seek-R1 improves prediction accuracy by 22.04% and anomaly localization mIoU by 13.9% compared with existing methods, demonstrating strong generalization in complex environments and out-of-distribution scenarios.
Conference on Neural Information Processing Systems(NeurIPS),2025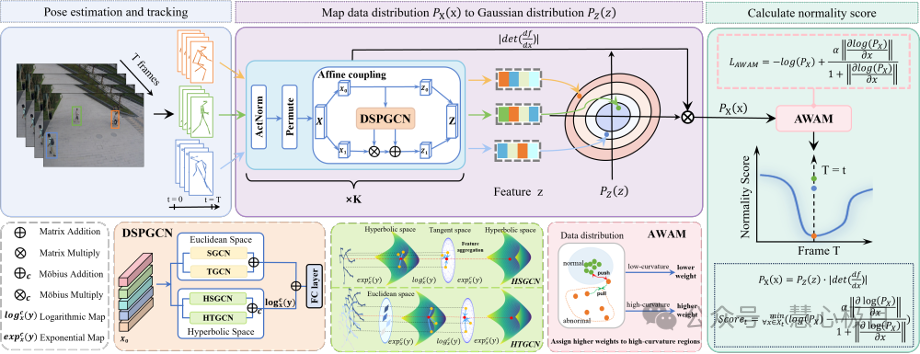
Dual-space Normalizing Flow for Unsupervised Video Anomaly
Detection
Jiaxu Leng, Yumeng Zhang, Mingpi Tan, Changjiang Kuang, Zhanjie Wu, Ji Gan,
Xinbo Gao*
Since existing flow-based methods are limited to Euclidean space and struggle to distinguish ambiguous abnormal actions that resemble normal ones, this paper proposes a novel unsupervised video anomaly detection method based on bi-space normalizing flows. This approach integrates the advantages of both Euclidean and hyperbolic geometry, capturing the intrinsic hierarchical relationships between actions while extracting fine-grained local features of human poses. Additionally, it incorporates an adaptive-weighted approximate quality loss that dynamically applies stronger constraints to less discriminative regions, encouraging the model to focus more on key discriminative features that reflect complex inter-action relationships. Extensive experiments on public datasets demonstrate the method's effectiveness and robustness across various video anomaly detection scenarios.
IEEE Transactions on Image Processing(TIP),2025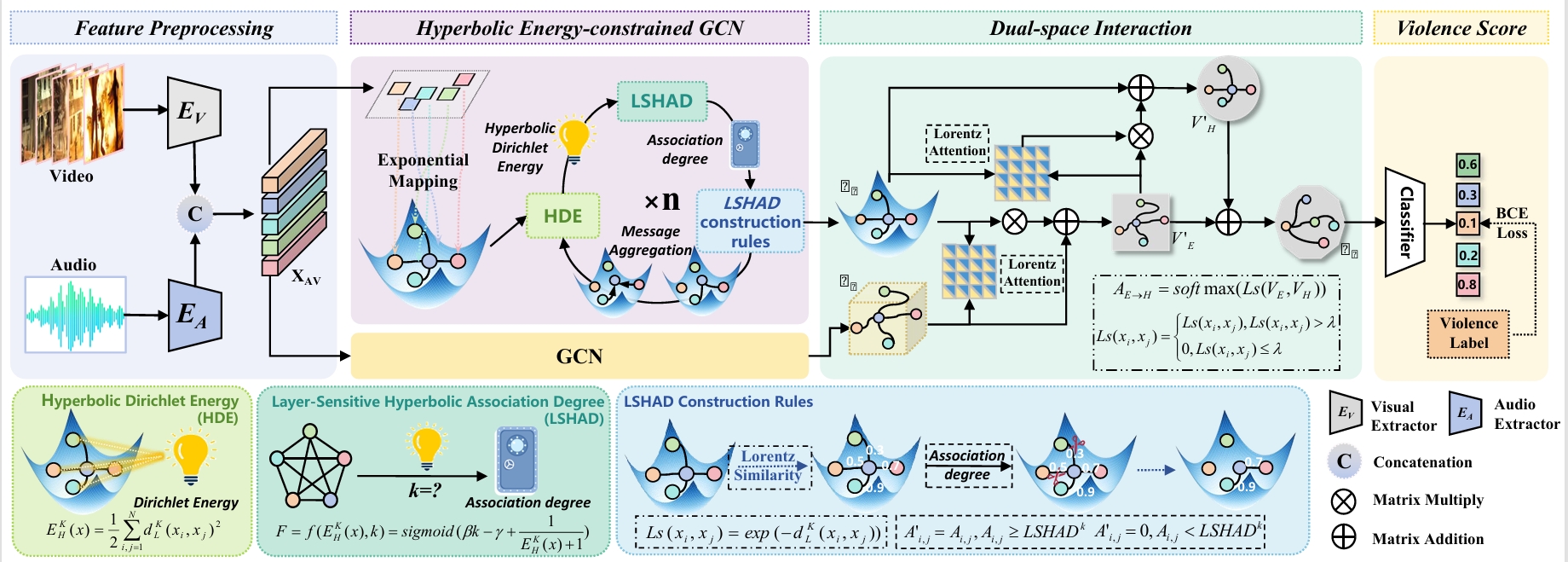
Beyond Euclidean: Dual-Space Representation Learning for Weakly
Supervised Video Violence Detection
Jiaxu Leng, Zhanjie Wu, Mingpi Tan, Yiran Liu, Ji Gan, Haosheng Chen, and
Xinbo Gao*
While numerous Video Violence Detection (VVD) methods have focused on representation learning in Euclidean space, they struggle to learn sufficiently discriminative features, leading to weaknesses in recognizing normal events that are visually similar to violent events (i.e., ambiguous violence). In contrast, hyperbolic representation learning, renowned for its ability to model hierarchical and complex relationships between events, has the potential to amplify the discrimination between visually similar events. Inspired by these, we develop a novel Dual-Space Representation Learning (DSRL) method for weakly supervised VVD to utilize the strength of both Euclidean and hyperbolic geometries, capturing the visual features of events while also exploring the intrinsic relations between events, thereby enhancing the discriminative capacity of the features. DSRL employs a novel information aggregation strategy to progressively learn event context in hyperbolic spaces, which selects aggregation nodes through layer-sensitive hyperbolic association degrees constrained by hyperbolic Dirichlet energy. Furthermore, DSRL attempts to break the cyber-balkanization of different spaces, utilizing cross-space attention to facilitate information interactions between Euclidean and hyperbolic space to capture better discriminative features for final violence detection.
Advances in Neural Information Processing Systems (NeurIPS), 2024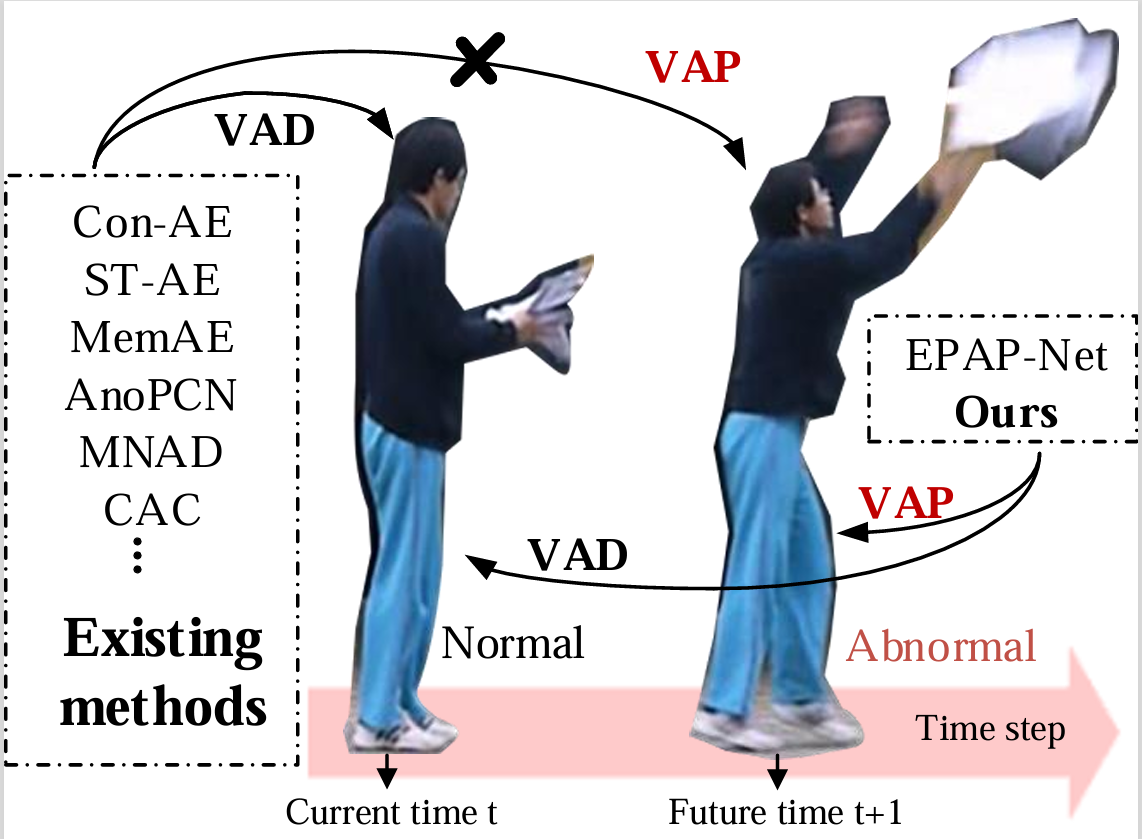
Anomaly Warning: Learning and Memorizing Future Semantic Patterns
for Unsupervised Ex-ante Potential Anomaly Prediction
Jiaxu Leng, Mingpi Tan, Xinbo Gao*, Wen Lu and Zongyi Xu
Existing video anomaly detection methods typically utilize reconstruction or prediction error to detect anomalies in the current frame. However, these methods cannot predict ex-ante potential anomalies in future frames, which is imperative in real scenes. Inspired by the ex-ante prediction ability of humans, we propose an unsupervised Ex-ante Potential Anomaly Prediction Network (EPAP-Net), which learns to build a semantic pool to memorize the normal semantic patterns of future frames for indirect anomaly prediction. At the training time, the memorized patterns are encouraged to be discriminated through our Semantic Pool Building Module (SPBM) with the novel padding and updating strategies. Moreover, we present a novel Semantic Similarity Loss (SSLoss) at the feature level to maximize the semantic consistency of memorized items and corresponding future frames. Specially, to enhance the value of our work, we design a Multiple Frames Prediction module (MFP) to achieve anomaly prediction in future multiple frames. At the test time, we utilize the trained semantic pool instead of ground truth to evaluate the anomalies of future frames. Besides, to obtain better feature representations for our task, we introduce a novel Channel-selected Shift Encoder (CSE), which shifts channels along the temporal dimension between the input frames to capture motion information without generating redundant features. Experimental results demonstrate that the proposed EPAP-Net can effectively predict the potential anomalies in future frames and exhibit superior or competitive performance on video anomaly detection.
ACM International Conference on Multimedia (ACM MM), 2022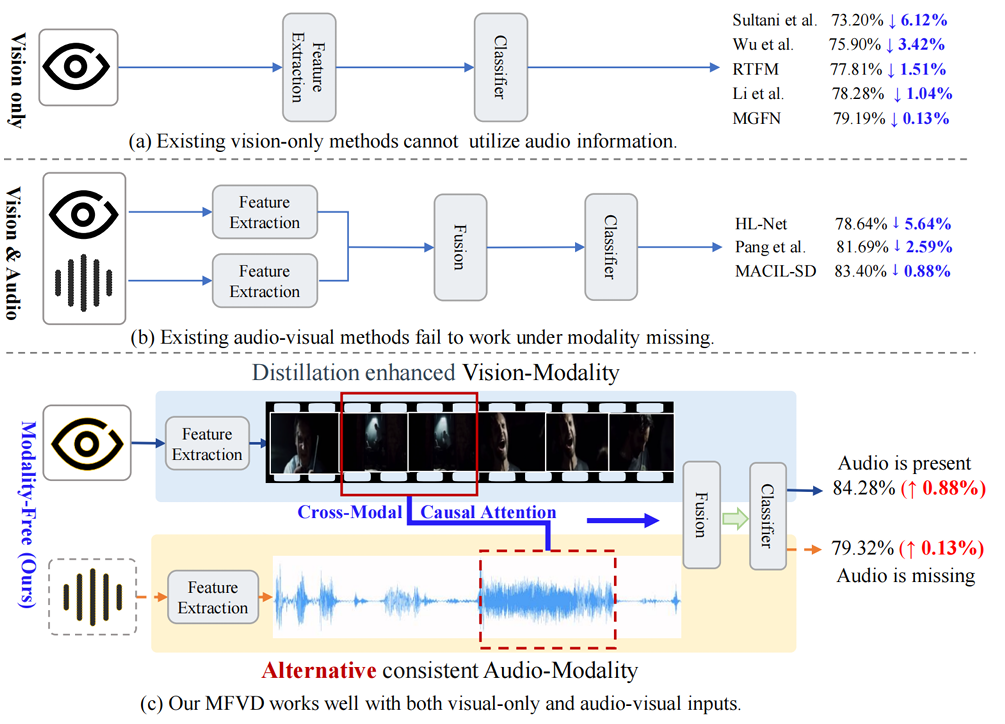
Modality-Free Violence Detection via Cross-Modal Causal Attention
and Feature Distillation
Jiaxu Leng, Zhanjie Wu, Mengjingcheng Mo, Mingpi Tan, Shuang Li, Xinbo Gao*
In this paper, we propose a novel framework, Modality-Free Violence Detection (MFVD), which captures the causal relationships among multimodal cues and ensures stable performance even in the absence of audio information. Specifically, we design a novel Cross-Modal Causal Attention mechanism (CCA) to deal with modality asynchrony by utilizing relative temporal distance and semantic correlation to obtain causal attention between audio and visual information instead of merely calculating correlation scores between audio and visual features. Moreover, to ensure our framework can work well when the audio modality is missing, we design a Cross-Modal Feature Distillation module (CFD), leveraging the common parts of the fused features obtained from CCA to guide the enhancement of visual features. Experimental results on the XD-Violence dataset demonstrate the superior performance of the proposed method in both vision-only and audio-visual modalities, surpassing state-of-the-art methods for both tasks.
IEEE International Conference on Multimedia and Expo (ICME), 2024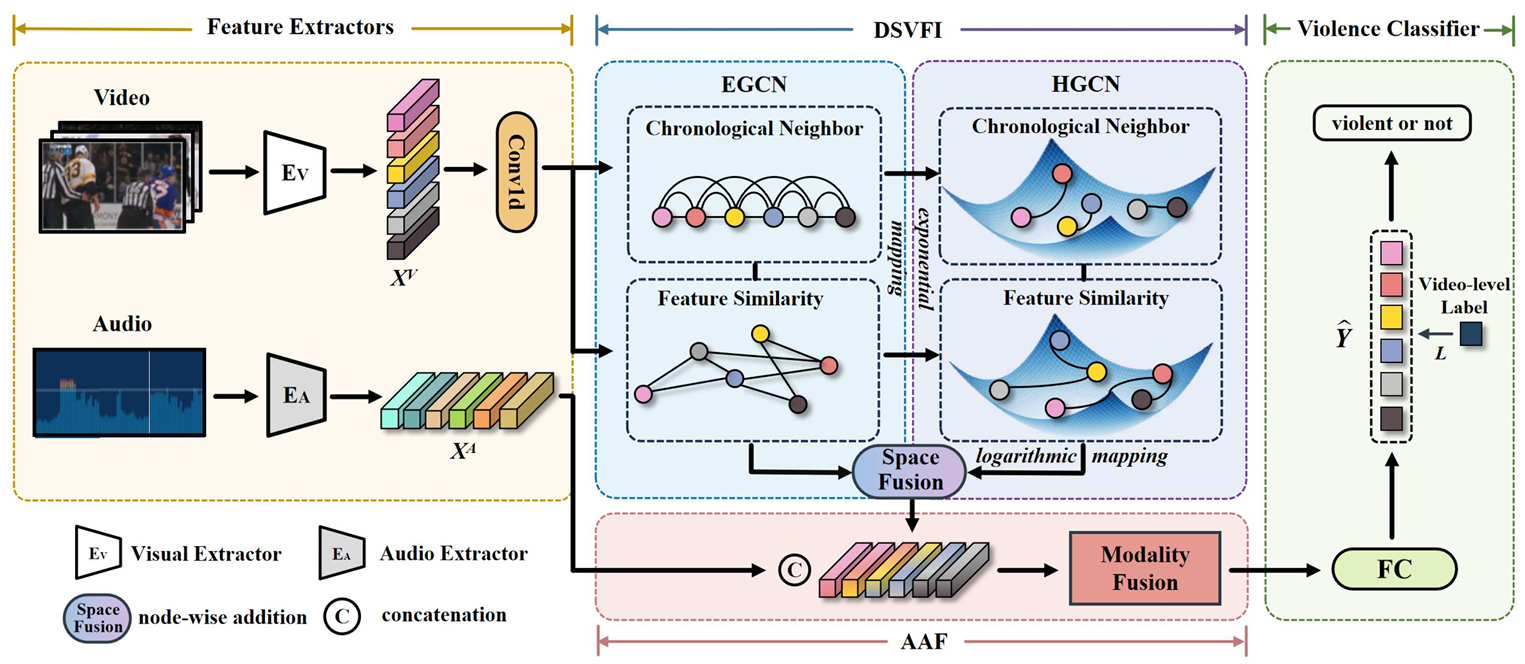
Dual Space Embedding Learning For Weakly Supervised Audio-Visual
Violence Detection
Yiran Liu, Zhanjie Wu, Mengjingcheng Mo, Ji Gan, Jiaxu Leng*, Xinbo Gao*
In this paper, we propose Dual Space Embedding Learning (DSEL) for weakly supervised audio-visual violence detection, which excavates violence information deeply in both Euclidean and Hyperbolic spaces to distinguish violence from non-violence semantically and alleviate the asynchronous issue of violent cues in audio-visual patterns. Specifically, we first design a dual space visual feature interaction module (DSVFI) to deeply investigate the violence information in visual modality, which contains richer information compared to audio counterpart. Then, considering the modality asynchrony between the two modalities, we employ a late modality fusion method and design an asynchrony-aware audio-visual fusion module (AAF), in which visual features receive the violent prompt from the audio features after interacting among snippets and learning the violence information from each other. Experimental results show that our method achieves state-of-the-art performance on XD-Violence.
IEEE International Conference on Multimedia and Expo (ICME), 2023

Weixin Applet
Ipsum ipsum clita erat amet dolor justo diam
Chicken Burger $115
Ipsum ipsum clita erat amet dolor justo diam


